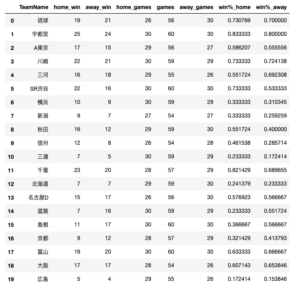
【練習】チームの得点とFourFactorsの関係について【マルチレベルモデル】
こんにちは、らんそうるいです。『Rで学ぶマルチレベルモデル 入門編』というテキストが手に入ったので、マルチレベルモデルによる分析の練習をしたいと思います。分析のお作法の話なので、分析手法に興味のない方にとってはあまり面白くないと思います。申し訳ございません。
今回題材にするのは、チームの得点とFour Factorsの関係です。Four Factorsというのはバスケで重要とされている攻撃指標の総称で、eFG%, TO%, FT%, ORB%の4つです。詳しい説明はこちらの記事が参考になると思います→バスケットボールを数字で分解する。~みんなに知ってほしいFour Factors~。
得点とeFG%, FT%, ORB%が正の相関関係を示すこと、TO%は負の相関関係を示すのは、当然のこととして、今回問題にしたいのは、それらの推定方法です。バスケのデータでは、得点とFour Factorsがチームごとに得られます。図にするとこんな感じ(↓)です。チームごとに得点・Four Factorsが得られるこのようなデータセットのことを、前述したテキストでは「複数のレベルを持つデータ」と呼んでいました。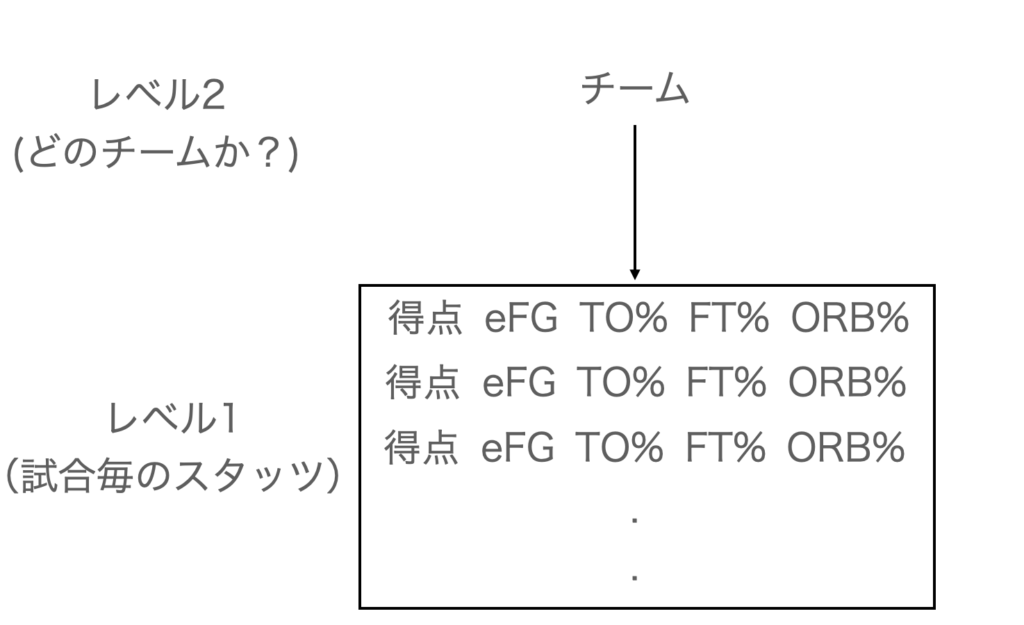
この記事の目的2つです。1つ目は、おそらくデータの階層性を考慮して得点とFour Factorsの関係を検討した記事はないので、それを調べることです。2つ目の目的は、マルチレベルモデルによる分析を、階層性を無視した分析、チームごとの平均得点・Four Factorsを使った分析と比較してみることです。特に後者のチームごとの平均スタッツを使う分析は、マルチレベルモデルによる分析とニュアンスが近く、(一部の方にとっては)興味深い比較になるのではないかと思います。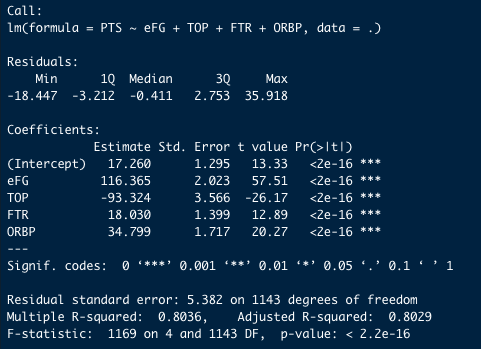
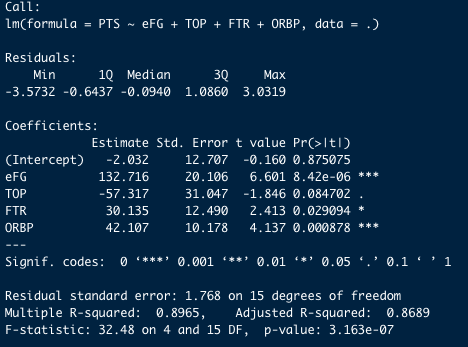
この結果はかなり小さいサンプルサイズ(n=20)で分析を行っているからだと考えられます。チームごとに平均をとったため、せっかく全試合について得点・Four Factorsのデータがあるのに、それを集約して(悪い言い方をすれば「捨てて」)しまっています。データが有効活用できていないと言えます。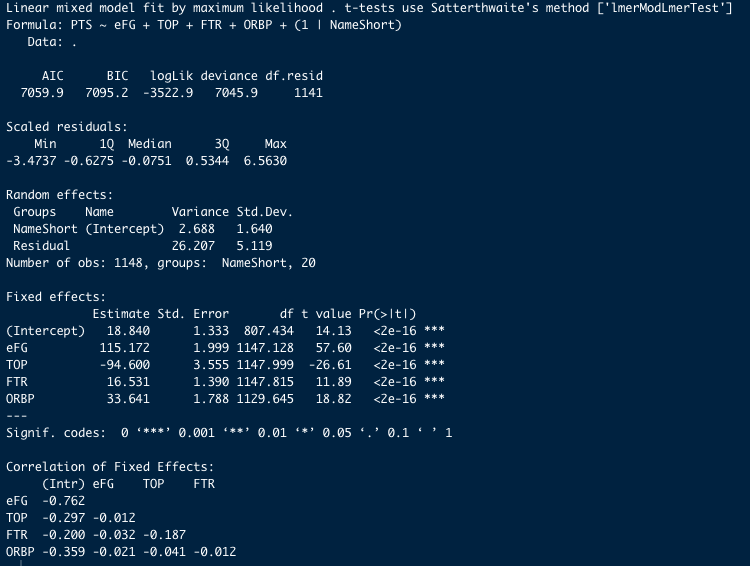
マルチレベルモデルを使うと、チームごとの違いを考慮しつつ、推定精度を落とさずに分析できることが分かりました(階層性を無視したモデルと比べて、推定精度がほとんど変わらないので、階層性についてナーバスにならなくても良いということも言えるかもしれません)。
階層性を無視した重回帰モデルと、マルチレベルモデルの予測精度をAICで比較した結果、前者が7129.337、後者が7059.869という結果が得られました。つまり、マルチレベルモデルの方が得点をFour Factorsから正確に予測できていたことになります。これは、マルチレベルモデルではチームごとに切片を設定しているのが効いているのだと思います。
そこで、チーム毎の効果の影響を除くために使われるのが、集団平均中心化(centering within cluster, CWC)です。集団平均中心化は各試合のFour Factorsから、そのチームのFour Factorsの平均を引くことで行います。こうすることで、チーム毎のFour Factorsのばらつきが0になります。結果として、マルチレベルモデルの偏回帰係数は「そのチームのFour Factorsの平均値よりも、値が大きく(小さく)なったときの、得点への影響」となり、より純粋な得点とFour Factorsの関係を調べることができます。
集団平均中心化を施したFour Factorsと得点の関係を調べた分析結を次に示します。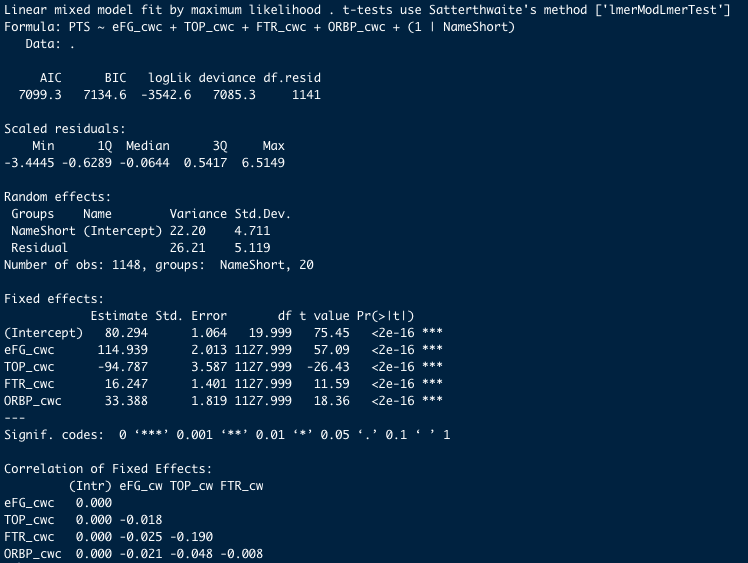
マルチレベルモデルを使った分析は初めてなので、間違いや質問などがございましたら、お気軽にお寄せください(らんそうるい)。ただ、私も勉強中なので的確に答えられるかは保証できません。
○南風原. (2014)『続・心理統計学の基礎──統合的理解を広げ深める』. 有斐閣.

今回題材にするのは、チームの得点とFour Factorsの関係です。Four Factorsというのはバスケで重要とされている攻撃指標の総称で、eFG%, TO%, FT%, ORB%の4つです。詳しい説明はこちらの記事が参考になると思います→バスケットボールを数字で分解する。~みんなに知ってほしいFour Factors~。
得点とeFG%, FT%, ORB%が正の相関関係を示すこと、TO%は負の相関関係を示すのは、当然のこととして、今回問題にしたいのは、それらの推定方法です。バスケのデータでは、得点とFour Factorsがチームごとに得られます。図にするとこんな感じ(↓)です。チームごとに得点・Four Factorsが得られるこのようなデータセットのことを、前述したテキストでは「複数のレベルを持つデータ」と呼んでいました。
この記事の目的2つです。1つ目は、おそらくデータの階層性を考慮して得点とFour Factorsの関係を検討した記事はないので、それを調べることです。2つ目の目的は、マルチレベルモデルによる分析を、階層性を無視した分析、チームごとの平均得点・Four Factorsを使った分析と比較してみることです。特に後者のチームごとの平均スタッツを使う分析は、マルチレベルモデルによる分析とニュアンスが近く、(一部の方にとっては)興味深い比較になるのではないかと思います。
データセット
rintaromasuda様のGitHubからteams.csvとgames_summary_202021.csvをダウンロードし、これらを生データとしました。B1のチームだけを分析対象にしました。分析
前述した記事の目的と順番が逆になりますが、マルチレベルモデルによる分析を、階層性を無視した分析、チームごとの平均得点・Four Factorsを使った分析と比較した後、データの階層性を考慮して得点とFour Factorsの関係を検討します。同じチーム内では得点は似通っているのか?
マルチレベルモデルを使うべきかどうかを決める判断材料の一つに、チーム内での得点が似通っているのか? という視点があります。統計学では、級内相関係数という指標でこれを評価することができます。得点の級内相関係数を調べた結果、0.146[95%CI=0.058, 0.234]という結果が得られました。つまり「観測値の独立性の仮定」を破っている可能性が高いことが分かりました。階層性を無視した分析(重回帰分析)
まず階層性を無視した重回帰分析の結果を次に示します。チームごとの平均スタッツを用いた分析(重回帰分析)
チームごとの平均スタッツを用いた重回帰分析の結果を次に示します。この結果はかなり小さいサンプルサイズ(n=20)で分析を行っているからだと考えられます。チームごとに平均をとったため、せっかく全試合について得点・Four Factorsのデータがあるのに、それを集約して(悪い言い方をすれば「捨てて」)しまっています。データが有効活用できていないと言えます。
階層性を考慮した分析(マルチレベルモデル)
マルチレベルモデルの中でもランダム切片モデルを用いました。本当は「ランダム切片・傾きモデル」が望ましいと思うのですが、エラーがでてしまうので、ランダム切片モデルの結果を報告します。結果は次のようになりました。マルチレベルモデルを使うと、チームごとの違いを考慮しつつ、推定精度を落とさずに分析できることが分かりました(階層性を無視したモデルと比べて、推定精度がほとんど変わらないので、階層性についてナーバスにならなくても良いということも言えるかもしれません)。
階層性を無視した重回帰モデルと、マルチレベルモデルの予測精度をAICで比較した結果、前者が7129.337、後者が7059.869という結果が得られました。つまり、マルチレベルモデルの方が得点をFour Factorsから正確に予測できていたことになります。これは、マルチレベルモデルではチームごとに切片を設定しているのが効いているのだと思います。
チームの違いを考慮した得点とFour Factorsの関係(集団平均中心化を使った分析)
マルチレベルモデルでFour Factorsを独立変数として置く際、値をそのまま使うと、Four Factorsの絶対的な大きさが得点にどれだけ影響するかを調べることになります。この場合、偏回帰係数は試合毎の効果(←今回関心のあること)とチーム毎の効果が混ざった値になります。そこで、チーム毎の効果の影響を除くために使われるのが、集団平均中心化(centering within cluster, CWC)です。集団平均中心化は各試合のFour Factorsから、そのチームのFour Factorsの平均を引くことで行います。こうすることで、チーム毎のFour Factorsのばらつきが0になります。結果として、マルチレベルモデルの偏回帰係数は「そのチームのFour Factorsの平均値よりも、値が大きく(小さく)なったときの、得点への影響」となり、より純粋な得点とFour Factorsの関係を調べることができます。
集団平均中心化を施したFour Factorsと得点の関係を調べた分析結を次に示します。
まとめ
この記事では、階層性を無視した分析と考慮した分析の結果を比較しました。その結果、階層性を無視した分析と考慮した分析では、後者の方が予測精度は高いものの、分析結果はそう変わらないということが分かりました(今回の分析ではたまたまそうなっただけで、いつも変わらないのかは分かりません)。また、集団平均中心化を施したFour Factorsと得点の関係をマルチレベルモデルで検討しました。その結果、Four Factorsたちは直感に沿う方向で得点と相関していることが分かりました。マルチレベルモデルを使った分析は初めてなので、間違いや質問などがございましたら、お気軽にお寄せください(らんそうるい)。ただ、私も勉強中なので的確に答えられるかは保証できません。
参考文献
○尾崎・川端・山田. (2018).『Rで学ぶマルチレベルモデル入門編 基本モデルの考え方と分析』. 朝倉書店.○南風原. (2014)『続・心理統計学の基礎──統合的理解を広げ深める』. 有斐閣.
分析に使ったコード(R)
#必要なライブラリのインポート
library(tidyverse)
#データのインポート
summary=read_csv("games_summary_202021.csv")
teams=read_csv("teams.csv")
#2020-21 B1のチームだけ抽出
teams_2021_B1=teams %>% filter(Season=="2020-21") %>% filter(League=="B1")
#データをjoinする
data=teams_2021_B1 %>% left_join(summary,by="TeamId")
#FourFactoesを計算
data=data %>% mutate(eFG=((F2GM+F3GM)+0.5*F3GM)/(F2GA+F3GA))
data=data %>% mutate(TOP=TO/((F2GA+F3GA)+0.44*FTA+TO))
data=data %>% mutate(FTR=FTA/(F2GA+F3GA))
data=data %>% arrange(ScheduleKey)
kisu=seq(1,1148,2)
gusu=seq(2,1148,2)
data_k=data[kisu,]
data_g=data[gusu,]
ORBP_k=data_frame(NameShort=data_k$NameShort,
ScheduleKey=data_k$ScheduleKey,
ORBP=data_k$OR/(data_k$OR+data_g$DR))
ORBP_g=data_frame(NameShort=data_g$NameShort,
ScheduleKey=data_g$ScheduleKey,
ORBP=data_g$OR/(data_g$OR+data_k$DR))
ORBP=rbind(ORBP_k,ORBP_g)
data=data %>% left_join(ORBP,by=c("NameShort","ScheduleKey"))
data2=data %>% select(NameShort,PTS,eFG,TOP,FTR,ORBP)
#普通の回帰分析
model=data2 %>% lm(PTS~eFG+TOP+FTR+ORBP,data=.)
summary(model)
#チームごとに平均をとって回帰分析
data3=data2 %>% group_by(NameShort) %>% summarise(PTS=mean(PTS),
eFG=mean(eFG),
TOP=mean(TOP),
FTR=mean(FTR),
ORBP=mean(ORBP))
model2=data3 %>% lm(PTS~eFG+TOP+FTR+ORBP,data=.)
summary(model2)
#マルチレベルモデルを使う
#集団平均中心化を行う
data2=data2 %>% mutate(PTS_cwc=PTS-ave(data2$PTS,data2$NameShort))
data2=data2 %>% mutate(eFG_cwc=eFG-ave(data2$eFG,data2$NameShort))
data2=data2 %>% mutate(TOP_cwc=TOP-ave(data2$TOP,data2$NameShort))
data2=data2 %>% mutate(FTR_cwc=FTR-ave(data2$FTR,data2$NameShort))
data2=data2 %>% mutate(ORBP_cwc=ORBP-ave(data2$ORBP,data2$NameShort))
data2
#級内相関係数を求める
library(ICC)
data2 %>% ICCest(NameShort,PTS,data=.,alpha=0.05,CI.type="Smith")
#得点には級内相関係数が認められる。したがって、マルチレベルモデルの適用を考える
#ランダム切片モデルを立てる
library(lmerTest)
model_1=data2 %>% lmer(PTS~eFG_cwc+TOP_cwc+FTR_cwc+ORBP_cwc+(1|NameShort),data=.,REML=FALSE)
summary(model_1)
#ランダム切片・傾きモデルを立てる → エラーが出る
#model_2=data2 %>% lmer(PTS~eFG_cwc+TOP_cwc+FTR_cwc+ORBP_cwc+(1+eFG_cwc+TOP_cwc+FTR_cwc+ORBP_cwc|NameShort),data=.,REML=FALSE)
#summary(model_2)
#集団平均中心化を行わないモデルを立てる
model_2=data2 %>% lmer(PTS~eFG+TOP+FTR+ORBP+(1|NameShort),data=.,REML=FALSE)
summary(model_2)
#階層性を無視したモデルと、取り入れたモデルの比較
summary(model)
summary(model_1)
summary(model)
summary(model_2)
AIC(model)
AIC(model_2)
#AICで比較すると、階層性を考慮したモデルのほうが予測精度が高いFollow me!