Offensive Efficiencyで選手のプレータイムを回帰する
統計検定2級の勉強をしているらんそうるいです。回帰分析について学習したので、2020-21シーズンのB1のボックススコアから選手のプレータイムをOffensive Efficiency(OE)で回帰した結果について記事を書きました。特に、OEによるプレータイムの予測が大きく外れたとき(=残差が大きいとき)に注目したいと思います。チームのOEで勝ち試合数を回帰したときの残差が失点と負の相関を示すことが分かっている(https://rnsr0371.boy.jp/2021/03/20/oe_residuals/)ため、選手個人の残差もディフェンスでの貢献を表している可能性があると考えたためです。守備の評価はボックススコアでは難しいため、ボックススコアのデータから守備を評価する方法を見つけることは重要だと思います。また、OEは攻撃の効率を評価する指標ですが、その限界を探る上でも残差に注目することは意味があると思います。
分析の結果を先に書くと、①プレータイムをOEで回帰したときの決定係数は0.16程度です。②残差の大きい選手上位25人から推測するに、選手個人のOEの残差は守備の指標として使えないと考えられました。上位25人のほとんどは外国籍選手で、数少ない日本人選手の多くは3Pシューターでした。OEの目的を考えるとランクインした日本人選手に3Pシューターが多かったことは重要で、3Pシューターのフロアを広げる役割がOEでは評価できないため、3Pシューターの攻撃への貢献が過小評価される傾向があるのかもしれません。
Offensive Efficiencyとは?
OEはShea & Baker で提案されたスタッツで「その選手が終わらせたポゼッションの内、得点またはアシストがついたポゼッションの割合」を意味する。数式を確認すると、Four Factorsとよく似た視点の分析であることがよく分かる。
OE=(フィールドゴール成功数+アシスト数)/(フィールドゴール試投数+ターンオーバー数+アシスト数−オフェンシブリバウンド数)
OEでは得点・アシストが付いたポゼッションを分子が表しており、分母はある選手(またはチーム)が終わらせたポゼッションを近似している。また、オフェンシブリバウンドは攻撃機会を増やす、つまりターンオーバーとは逆の指標であると考えられるので、TOとは逆にマイナスの符号で分母に投入されている。
OEは基本的には0〜1の値を取り、大きいほうが攻撃の効率が良い。これは終わらせたポゼションに占める、得点に結びついた割合が多いと解釈できるからである。
チームのOffensive EfficiencyはBリーグの試合の勝敗を効果的に予測するか? https://rnsr0371.boy.jp/2019/12/29/offensive_efficiency_1/
データセット
rintaromasuda様のgithub(https://github.com/rintaromasuda/bleaguer/tree/master/inst/extdata)からデータをダウンロードしました。分析に用いたデータはgames_box_score_202021.csv, teams.csvです。
ここから、各選手の平均スタッツを算出しました。その後、OEを計算し、平均出場時間をOEで回帰しました。
なお分析対象はB1の選手のみです。
結果
OEでプレータイムを回帰した結果
OEとプレータイム(MIN)の散布図は以下のようになりました。モデルの決定係数は0.16程度と高くはありませんでした。

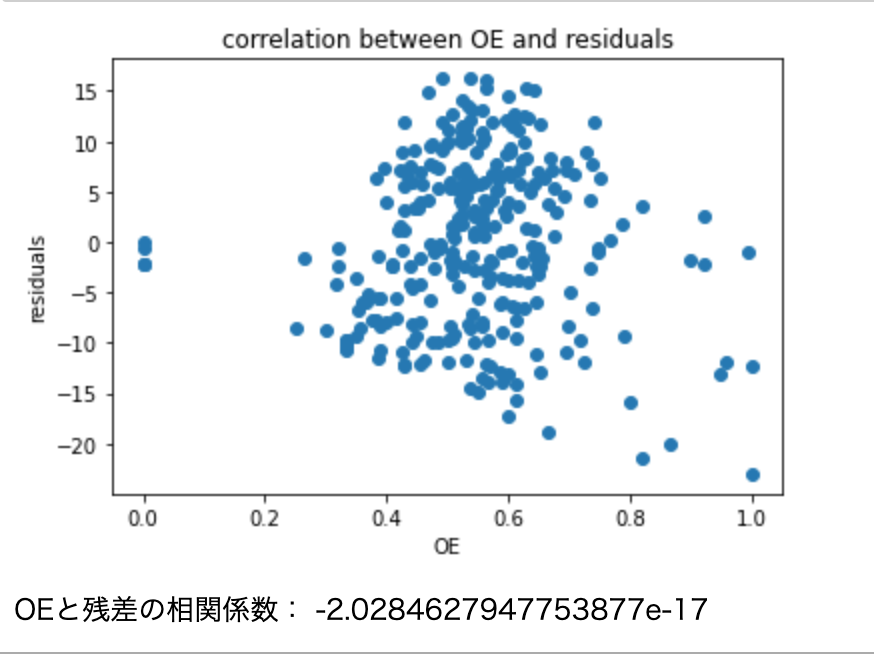
続いて、OEと残差の相関は次の図のようになりました。理論から予測される通り、残差は平均が0で、独立変数(OE)と相関がほとんどないという結果が確認できました。
残差に注目した分析
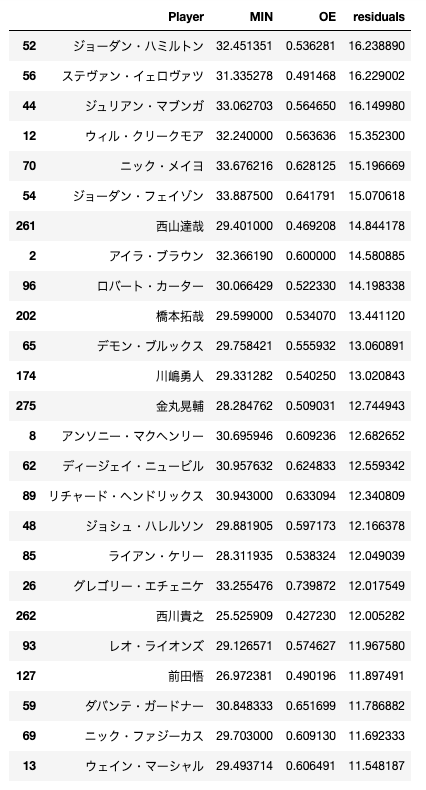
OEから予測されるよりも、プレータイムが長かった選手上位25名を次の表に示しました。外国籍選手が多いことと、日本人選手が少数ながらいることが分かります。
外国籍選手は身長が高いことが多く、コートにいるだけでリム周りのディフェンスが改善されるため、出場時間がOEから予測されるより長くなっているという仮説を立てました。また、数少ない日本人選手の中に3Pの名手金丸選手がいることから、3Pの得意な選手がランクインしている可能性を思いつきました。
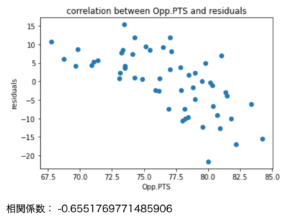
外国籍選手の守備への貢献をボックススコアから評価するのは難しいですが、リム周りのディフェンスが改善されるなら、たとえば残差が大きいほどディフェンシブリバウンド数(DR)も多いと予想できます。その可能性を検討するために、上位25名のDR数を示した表が次の表です。リーグのDR数の平均は2.00なので、ランクインした選手のDRは多い傾向があるのが分かりました。

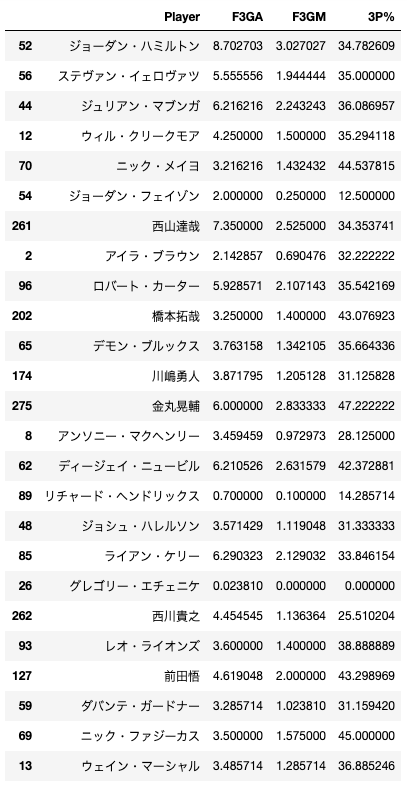
続いて3Pと残差の関係についてです。残差の大きい選手上位25人の3P試投数と3P成功数、成功率を示したのが次の表です。ランクインした日本人選手に注目すると、3P試投数が多い選手と成功率が高い選手が多い選手がランクインしていることが分かりました。
以上の結果をまとめた散布図が次のものです。残差とDRの散布図で色が濃いほど3P試投数・成功数が多くなるように作図しました。残差が大きいデータが、3Pを放つ選手・決める選手のグループとDRの多いグループに分かれているような気がしませんか?


相関係数を紹介しておくと、残差とDRが0.655、残差と3P試投数が0.733、残差と3P成功数が0.682、残差と3P成功率が0.098でした。
終わりに
OEで選手のプレータイムを回帰してみました。その結果、OEはプレータイムの分散をあまり説明できない(決定係数=0.16)ことが分かりました。また、残差が大きい選手は外国籍の選手と3Pシューターが多いことが分かりました。特に3Pシューターが多いということは重要で、OEが3Pシューターのフロアを広げる役割を過小評価している可能性が示唆されました。OEの限界を示唆する結果を得たのは初めてなので、ちょっと興奮しています。
また、OEが攻撃の効率を評価しているとして、あまり効率的ではない3Pシューターが試合に長く出ているということはちょっと驚きでした。3Pのスタッツに現れない重要性が垣間見えたのではないかと思います。打ち続けることが大事なんや……
分析に用いたコード(Python)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
import numpy as np
#データの読み込み
data=pd.read_csv("games_boxscore_202021.csv",encoding="UTF-8")
data
#マスターデータの読み込み
teams=pd.read_csv("teams.csv",encoding="UTF-8")
teams_2021=teams[teams["Season"]=="2020-21"]
#dataにチーム名をジョイン
data=data.merge(teams_2021,on="TeamId")
pd.set_option("display.max_columns",100)
#B1のデータだけ抽出
data=data[data["League"]=="B1"]
#選手の平均スタッツを作る
data2=data.groupby("Player").mean()
data2
#インデックスを振り直す
data2=data2.reset_index()
#OEを計算
OE=[]
for FGM,FGA,OR,AS,TO in zip(data2["FGM"],data2["FGA"],data2["OR"],data2["AS"],data2["TO"]):
if(FGA+AS+TO-OR)==0:
OE.append(np.nan)
else:
tempOE=(FGM+AS)/(FGA+AS+TO-OR)
OE.append(tempOE)
data2["OE"]=pd.DataFrame(OE)
data2
#NaNを除外する
data2=data2.dropna()
#OEとMINの相関の確認
x=data2[["OE"]]
y=data2[["MIN"]]
plt.plot(x,y,"o")
plt.xlabel("OE")
plt.ylabel("MIN")
plt.title("correlation between OE and MIN")
plt.show()
print("OEとMINの相関係数:",data2["OE"].corr(data2["MIN"]))
#OEでMINを回帰
model=LinearRegression()
model.fit(x,y)
#可視化など
plt.plot(x,y,"o")
plt.plot(x,model.predict(x),linestyle="solid")
plt.ylabel("MIN")
plt.xlabel("OE")
plt.title("correlation between OE and MIN")
plt.show()
print("モデルの回帰係数",model.coef_)
print("モデルの切片",model.intercept_)
print("決定係数",model.score(x,y))
#予測値をdata2に追加
pred=model.predict(x)
data2=data2.reset_index()
data2["MIN_pred"]=pd.DataFrame(pred)
data2
#残差をdata2に追加
res=[]
for MIN,MIN_pred in zip(data2["MIN"],data2["MIN_pred"]):
temp=MIN-MIN_pred
res.append(temp)
data2["residuals"]=pd.DataFrame(res)
data2
#残差とOEの相関を確認
plt.plot(data2["OE"],data2["residuals"],"o")
plt.xlabel("OE")
plt.ylabel("residuals")
plt.title("correlation between OE and residuals")
plt.show()
print("OEと残差の相関係数:",data2["OE"].corr(data2["residuals"]))
#残差の大きい選手上位25名を抽出
data3=data2.sort_values("residuals",ascending=False).head(25)
data3.loc[:,["Player","MIN","OE","residuals"]]
#外国籍選手が多くランクインしている→DRでの貢献?
#ランクインした日本人選手は3Pシューター?
#ランクインした選手のディフェンシブリバウンドを確認
data3.loc[:,["Player","DR"]]
#ランクインした選手の3P%を確認
data3["3P%"]=data3["F3GM"]/data3["F3GA"]*100
data3.loc[:,["Player","F3GA","F3GM","3P%"]]
#data2で残差とDRの相関をとる
plt.plot(data2[["residuals"]],data2[["DR"]],"o")
plt.xlabel("residuals")
plt.ylabel("DR")
plt.title("correlation between residuals and DR")
plt.show()
print("残差とDRの相関係数:",data2["residuals"].corr(data2["DR"]))
#残差とDRの相関(3P試投数で着色)
sns.scatterplot(x=data2["residuals"],y=data2["DR"],hue=data2["F3GA"],data=data2)
#残差とDRの相関(3P成功数で着色)
sns.scatterplot(x=data2["residuals"],y=data2["DR"],hue=data2["F3GM"],data=data2)
#data2で残差とF3GAの相関をとる
plt.plot(data2[["residuals"]],data2[["F3GA"]],"o")
plt.xlabel("residuals")
plt.ylabel("F3GA")
plt.title("correlation between residuals and F3GA")
plt.show()
print("残差と3P試投数の相関係数:",data2["residuals"].corr(data2["F3GA"]))
#data2で残差とF3GMの相関をとる
plt.plot(data2[["residuals"]],data2[["F3GM"]],"o")
plt.xlabel("residuals")
plt.ylabel("F3GM")
plt.title("correlation between residuals and F3GM")
plt.show()
print("残差と3P成功数の相関係数:",data2["residuals"].corr(data2["F3GM"]))
#data2で残差と3P%の相関をとる→相関なし
data2["3P%"]=data2["F3GM"]/data2["F3GA"]*100
plt.plot(data2[["residuals"]],data2[["3P%"]],"o")
plt.xlabel("residuals")
plt.ylabel("3P%")
plt.title("correlation between residuals and 3P%")
plt.show()
print("残差と3P%の相関係数:",data2["residuals"].corr(data2["3P%"]))
Follow me!