パディングを試してみた!
NBAのデータ分析では、パディング(padding)という手法が提案され、活用されています。スタッツには多少ノイズ(e.g., 運)が含まれるのですが、パディングはスタッツをうまくカサ増しすることによって、ノイズの軽減を狙う手法です。ノイズを軽減することによって、シーズン序盤の少ないデータから、シーズン終了時の最終的なスタッツを予測できるようになります。
パディングを行う方法はいくつか提案されています。一つ目は定数を用いたパディングです(e.g., NBA Stabilization Rates and the Padding Approach)。二つ目はベイズ推定を用いたパディング(e.g., シーズン序盤の3Pスタッツから最終的な3P%を予測します)です。この記事では、後者のベイズ推定を用いたパディングを試します。
ベイズ推定とは
「ベイズ推定とは「過去の経験」と「新たに得たデータ」をもとに不確実な事象を予測する手法」です(引用:ベイズ推定の簡単な例と利点)。
バスケットボールでベイズ推定を具体的に説明
この記事ではB1 2021-22レギュラーシーズンの富樫勇樹選手のFG%を題材にパディングを試します。
この題材において「過去の経験」として採用したのはB1 2020-21レギュラーシーズンの全選手のFG%です。そして「新たに得たデータ」はB1 2021-22レギュラーシーズンの各試合終了時点における富樫選手のFG%です。不確実な事象とは21-22レギュラーシーズン終了時点での富樫選手のFG%です。
ここで、過去の経験すなわちB1 2020-21レギュラーシーズン全選手のFG%の分布を確認してみましょう。ヒストグラムを確認すると、FG%が40%くらいの選手が多いことを読み取ることができます。富樫選手の21-22レギュラーシーズン終了時点のFG%も、だいたい40%くらいに落ち着くのではないかと予測することができます。
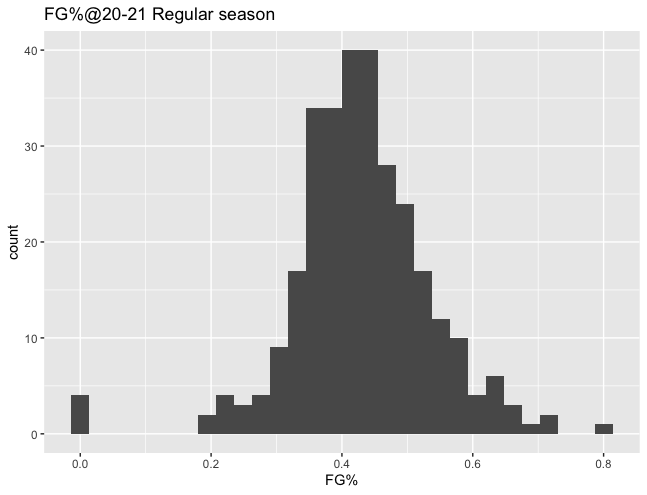
過去のデータから予測を立てましたが、21-22シーズンが始まり、1試合目が終わったとします。すると富樫選手の21-22シーズンのFG%が新たに得られます。そのFG%が40%よりも高ければ、21-22レギュラーシーズン終了時点の富樫選手のFG%は平均的な選手よりも高いのではないかと、予測を更新できます。
この予測の更新を「いい感じ」に行うのがベイズ推定です。
パディングの結果
B1 2021-22レギュラーシーズンの富樫選手の各試合終了時点のFG%を縦軸、試合数の経過を横軸にとった折れ線グラフが下図です。パディングをしていないFG%をraw(水色)、パディングしたFG%をpadded(赤色)としてプロットしています。折れ線グラフの読み方ですが、たとえば横軸が3であれば、3試合分のデータを用いた富樫選手のFG%を示しています。3試合目のデータだけを使ってFG%を計算しているわけではない点にご注意ください。
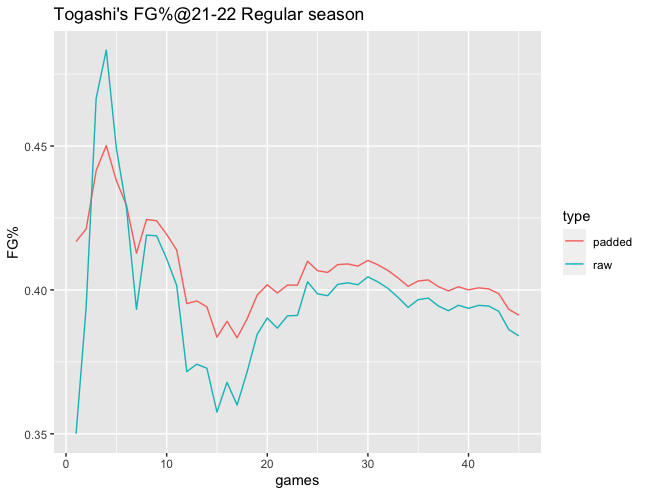
まず、折れ線グラフの上下動について見てみます。raw(水色)に比べて、padded(赤色)の方がFG%の上下動が全体的に小さくなっていることが分かります。また、raw(水色)では上下動が小さくなり始めるのが20試合経過後くらいからなのですが、padded(赤色)では15試合程度から上下動が小さくなり始めていることも分かります。これは、データ量をカサ増しした結果、ノイズの軽減が達成されたためだと解釈しています。
次に、折れ線グラフの位置関係について見てみます。raw(水色)に比べて、padded(赤色)の方がグラフの上側で推移していることが分かります。これは、データ量のカサ増しに20-21レギュラーシーズンのFG%を使っていてその平均値が40%程度であることと、富樫選手の21-22レギュラーシーズンのFG%が40%よりも低いことから、カサ増しするデータと富樫選手の実データを混ぜ合わせると、富樫選手のFG%が40%に近づくためだと解釈しています。
詳細
詳細では、ベイズ推定で仮定したことについて説明します。
パディングされたFG%の定義
富樫選手の21-22レギュラーシーズンのパディングされたFG%=パディングされた富樫選手のFGM / パディングされた富樫選手のFGA
- パディングされた富樫選手のFGM=
富樫選手の21-22レギュラーシーズンのFGA×富樫選手の21-22レギュラーシーズンのFG%
+パディング値×20-21レギュラーシーズン全選手のFG%の平均値
- パディングされた富樫選手のFGA=富樫選手の21-22レギュラーシーズンのFGA+パディング値
推定したモデル
パディング値〜Normal(100, 10)
富樫選手の21-22シーズンのFG%〜Normal(パディングされたFG%、20-21レギュラーシーズンの全選手のFG%の分散)
実データからパディング値とパディングされたFG%を推定しました。
stanのコード
data {
real fgp_togashi;//その試合までの富樫のFG成功率
int fga_togashi;//その試合までの富樫のFG試投数
real fgp_mean;//昨シーズンの平均FG成功率
real fgp_sd;//昨シーズンのFG成功率の標準偏差
}
parameters {
real<lower=0>padding_value;
}
transformed parameters{
real<lower=0,upper=1>padded_fgp;
padded_fgp=(fga_togashi*fgp_togashi+padding_value*fgp_mean)/(fga_togashi+padding_value);
}
model {
padding_value~normal(100,10);
fgp_togashi~normal(padded_fgp,fgp_sd);
}
自分でもよく分からないこと
予測の更新を逐次的に行った方が直感的だと思います。B1 20-21レギュラーシーズンの全選手の平均FG%を事前分布とします。21-22レギュラーシーズンの一試合目が終わったら、事前分布を更新して事後分布を得ます。二試合目が終わったら、一試合目が終わった時点の事後分布を事前分布として使って、二試合目のデータで新たな事後分布を得ます。このように、試合が終わるたびにベイズ推定を逐次的に行った方が、人間の直感に近いと思います。そして、人間の直感に近いことはたぶん良いことだと思います。今回の実装では、このような逐次的な更新は実装できていないです。
富樫選手のFG%が正規分布から発生していると仮定した上で、その正規分布の平均値をパディングされたFG%として推定しているわけですが、FG%が正規分布するというのは現実に即していない仮定です。前掲のヒストグラム(B1 20-21レギュラーシーズンの全選手のFG%)をご覧いただければ分かるのですが、normal(FG%の平均, FG%の分散)をパラメタとした正規分布よりも、尖った分布をしています。
パディング値が平均100・分散10の正規分布から発生するという仮定が自分でもよく分からないです。よく分からない場合は無情報事前分布として、分散に大きな値を持つ正規分布を指定するのがセオリーのようなのですが、セオリー通りに推定するとパディング値が非常に大きな値になりました。そこで、NBA Stabilization Rates and the Padding Approachを参考に分布を決め打ちしたのですが、NBAのデータとBリーグのデータという違いがあるため、望ましくないと思います。Bリーグのデータ駆動でパディング値の分布を推定した方が良いと思います。
Follow me!