【バスケットボール】ボックススコアに残らないオフェンスへの貢献はどれくらいあるのか?
【記事が長くなったので先に結論を書きます。ボックススコアに残らない貢献は「かなりある」というのが私の中での結論です。】
【2021/06/11 追記:コードに書いてあるTS%の計算が間違っているとのご指摘を頂いたので、正しいコード&図に差し替えました。】
こんにちは、らんそうるいです。最近、Bリーグ版PIPM(https://b-impactmetrics.amebaownd.com/)が公開されて、ボックススコアに残らない貢献を数値化できる指標に関心があります。
「ボックススコアに残らない貢献」というのは、優れた3Pシュータがフロアにスペースを作りドライブするコースを作りやすくすることや、屈強なビッグマンがスクリーンでエースのプレーをお膳立てすることなどを私はイメージしています。これら「ボックススコアに残らない貢献」も数値化する試みとして、+/-, APM(Adjusted Plus-Minus), RAPM(Regularized Adjusted Plus-Minus)などのプラスマイナス系の指標が開発されてきました。その流れの中でPIPM(Player Impact Plus-Minus)という指標があります。PIPMについての解説はこちら(https://b-impactmetrics.amebaownd.com/posts/18102348)やこちらの英語記事2つ(https://fansided.com/2018/01/11/nylon-calculus-introducing-player-impact-plus-minus/ https://www.bball-index.com/player-impact-plus-minus/)があります。
PIPMを簡単に説明すると、ある選手の各種ボックススコア(得点やリバウンドなど)でRAPMをweighted regressionすることによってボックススコアの値をRAPMで何点分の価値があるのか変換したものと、ある選手のOn-Offデータを調整したもの、そしてリーグの平均と比較したある選手のオフェンシブ/ディフェンシブレーティング(これも調整されています)の、3つのアドバンスドスタッツの和です。PIPMは攻撃面での貢献を評価したO-PIPMと、守備面での貢献を調整したものD-PIPMに分けることができます。
O-PIPMはプラスマイナス系の指標なので、「ボックススコアに残らない貢献」も捉えた指標です。ただ、ここでバスケがよく分からない私は次のような疑問を抱きました。「ボックススコアに残らない貢献ってどれくらいあるんだ?」。本稿では、この「ボックススコアに残らない貢献」がどれくらいあるのか調べるために、O-PIPMを「ボッコススコアに残っている貢献」で回帰分析することによって、分散説明率(決定係数、R^2とも呼ばれます)を求めて、「ボックススコアに残っている貢献」でO-PIPMのばらつきをどれくらい説明できるのかを調べます。この分析によって「ボックススコアに残らない貢献」と「残る貢献」の両方を捉えたO-PIPMを、「ボックススコアに残る貢献」と完全に相関する部分(=回帰分析による予測値)と、「ボックススコアに残る貢献」と全く相関しない部分(=回帰分析の残差)に分けることができます。「ボックススコアに残る貢献」と全く相関しない部分は、まさに「ボックススコアに残らない貢献(の少なくとも一部)」を反映していると考えられます。
「ボックススコアに残っている貢献」として、本稿ではPoint Per Possession (PPP)、True Shooting Percentage (TS%)、effective Field Goal Percentage (eFG%)を用います。TS%とeFG%は選手の攻撃効率を調べるためによく使われるので、O-PIPMと比較します。PPPはTS%とeFG%に比べてマイナーな印象がありますが、「ある選手が終わらせたポゼッション一回あたりの得点」という、直感的に理解しやすい攻撃効率を示した指標で、私が激推しているスタッツなので、O-PIPMと比較します。
データの準備
分析にはB1 2020-21シーズンのデータを用いました。
PPP、TS%、eFG%の準備
ボックススコアのデータはrintaromasuda様(https://github.com/rintaromasuda/bleaguer/tree/master/inst/extdata)のデータを用いました。
PPPの計算式は次のとおりです。https://susatama.com/2020/11/16/ppp%EF%BC%88points-per-possession%EF%BC%89%E3%81%A8%E3%81%AF%E4%BD%95%E3%81%8B/を参考にしました。
- PPP = 得点 / (フィールドゴール試投数 + (0.44 * フリースロー試投数) + ターンオーバー数)
TS%の計算式は次のとおりです。https://jasonkido.hatenablog.com/entry/2020/05/24/205025を参考にしました。
- TS% = 得点 / (2 * (フィールドゴール試投数 + 0.44 * フリースロー試投数)) * 100
eFG%の計算式は次のとおりです。https://jasonkido.hatenablog.com/entry/2020/02/08/114332を参考にしました。
- eFG% = (フィールドゴール成功数 + 0.5 * 3P成功数) / フィールドゴール試投数
O-PIPMの準備
O-PIPMはB League Impact Metrics様(https://twitter.com/B_ImpactMetrics)からいただきました。計算方法については、上述した英語記事2本が参考になると思います(もしgithubなどに計算に用いたコードがアップされていれば、計算方法を正確に理解する上でとても参考になるのですが、計算に用いたコードはインターネット上には存在しないようです)。
O-PIPMをPPP、TS%、eFG%で回帰する
O-PIPMをPPPで回帰する
O-PIPMとPPPを用いて描いた散布図を示します。オレンジ色の直線は回帰直線です。O-PIPMとPPPの相関係数は0.564となりました。単回帰分析において分散説明率は相関係数を2乗したものなので、分散説明率は0.318となります。「ボックススコアに残っている貢献」としてPPPを使うと、O-PIPMのばらつきは「スタッツに残っている貢献」で約32%説明可能だということが分かりました。逆を言えば、約68%のばらつきは説明できないことになります。この68%のばらつきが、PPP(ボックススコアに残っている貢献)で捉えきれなかった「ボックススコアに残らない貢献」の大きさです。
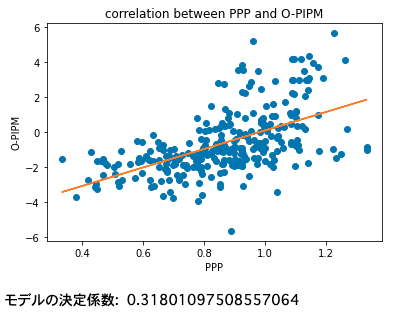
率直に感想を申し上げると、分散説明率が32%「しか」ないことは驚きでした。バスケの攻撃において、ボックススコアに記録されない貢献がこれほど大きいものだとは思いませんでした。私はバスケがほとんど分からないので、得点やアシストに目が行きがちなのですが、スクリーンやスペーシングなどにももっと目を向けて試合を観戦していきたいなと思いました。
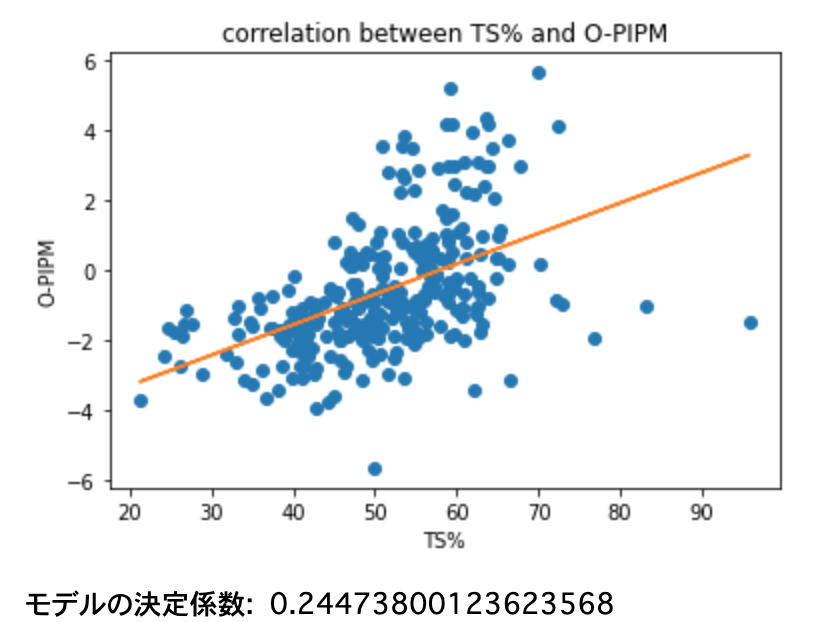
O-PIPMをTS%で回帰する
O-PIPMとTS%を用いて描いた散布図を示します。オレンジ色の直線は回帰直線です。O-PIPMとTS%の相関係数は0.498となりました。単回帰分析において分散説明率は相関係数を2乗したものなので、分散説明率は0.245となります。またしても、O-PIPMのばらつきをTS%はあまり説明できないということが分かりました。
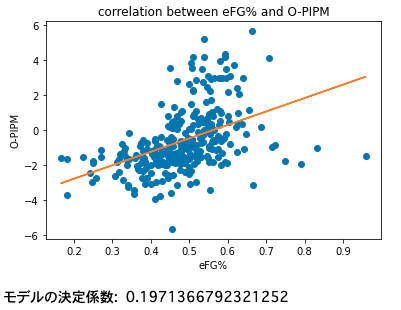
O-PIPMをeFG%で回帰する
O-PIPMとeFG%を用いて描いた散布図を示します。オレンジ色の直線は回帰直線です。O-PIPMとeFG%の相関係数は0.444となりました。単回帰分析において分散説明率は相関係数を2乗したものなので、分散説明率は0.197となります。
おまけ――O-PIPMをPPPで回帰したときに、残差が大きかった選手たち
PPPから予測されるよりもO-PIPMが高かった選手の上位25人を示したのが次のテーブルです。ここに載っている選手たちはPPPではあまり評価されなかったけれど、O-PIPMでは高く評価された選手たちと理解していただければ間違いがないと思います。ここに載っている選手たちについて考察すれば、ボックススコアに残らない貢献も捉えるO-PIPMが、具体的に何を評価しているのかのヒントになるはずです。

基本的にテーブルに載っている選手は外国籍選手でした。日本人選手では富樫、ベンドラメ、安藤誓哉、辻、斎藤拓実、長野誠史選手がランクインしました。日本人選手からのみ考察するとすれば、3Pが上手な選手とパスが上手い選手がランクインしているのではないかと思います。もう一つ傾向を挙げるとすれば、全員がボールハンドラーであることでしょうか。外国籍選手たちの傾向は分かりませんでした……。外国籍選手たちの傾向について何かアイディアがございましたら教えていただけると嬉しいです。
終わりに
この記事ではボックススコアに残らない貢献がどれくらいあるのか? を調べるために、ボックススコアに残る貢献の指標(PPP、TS%、eFG%)で、ボックススコアに残らない貢献も捉える指標(O-PIPM)を回帰分析しました。その結果、検討した中ではいちばん分散説明率が高かったPPPでさえ、30%ほどしかO-PIPMのばらつきを説明できないことが分かりました。分散説明率が約30%という結果を見て「ボックススコアから攻撃への貢献を思ったより評価できているな」と感じるか、それとも「ボックススコアから攻撃への貢献は部分的にしか評価できないな」と感じるかは人によって異なると思います。私は後者です。今回の結果は驚きで、衝撃的でした。
私はほとんどバスケが分からないので、データ分析からバスケを理解したいと思って記事を書いてきました。しかし、私が使っていたデータからは選手の貢献、それもほとんど攻撃面の一部しか評価できていなかったのはショックです。それと同時に、ボックススコアに残らない貢献だと思われる部分、スペーシングやスクリーンなどのプレーについての理解をもっと深めていきたいと思いました。
プラスマイナス系の指標は選手の貢献を数値化する上で優れた試みだと思います。日本のバスケのデータ分析界隈でもプラスマイナス系の指標がもっと使われていくと嬉しいのですが、プラスマイナス系の指標はデータセットの準備が手間です。Bリーグの公式サイトからデータをとってくるのはどうなんだ? という議論もあるとは思いますが、公式サイトでラインナップの得失点データやプラスマイナス系の指標が公開されると、データ分析が盛り上がると思うので、もし関係者の皆様がこの記事をご覧になってくれていたら、データの公開をぜひお願いしたいです。
最後に。快くデータの使用を承諾してくれたB League Impact Metrics様(https://twitter.com/B_ImpactMetrics)に感謝申し上げます。ありがとうございました。
【著者のTwitter:https://twitter.com/rnsr0371】
【この記事の続編→https://rnsr0371.boy.jp/2021/06/12/regress_pipm/】
分析に使ったコード(Python)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
pd.set_option("display.max_columns",100)
pd.set_option("display.max_rows",1000)
pipm=pd.read_csv("B1_20-21_PIPM 2_no_space.csv")
o_pipm=pipm[["選手名","O-PIPM"]]
o_pipm=o_pipm.rename(columns={"選手名":"Player"})
box=pd.read_csv("games_boxscore_202021.csv")
#PPPを計算する
ppp=[]
for pts,fga,fta,to in zip(box["PTS"],box["FGA"],box["FTA"],box["TO"]):
if fga+(0.44*fta)+to==0:
ppp.append(np.nan)
else:
ppp.append(pts/(fga+(0.44*fta)+to))
box["PPP"]=ppp
#TS%を計算する
ts=[]
for pts,fga,fta in zip(box["PTS"],box["FGA"],box["FTA"]):
if 2*(fga+0.44*fta)==0:
ts.append(np.nan)
else:
ts.append((pts/(2*(fga+0.44*fta))*100))
box["TS%"]=ts
#eFG%を計算する
efg=[]
for fgm,f3gm,fga in zip(box["FGM"],box["F3GM"],box["FGA"]):
if fga==0:
efg.append(np.nan)
else:
efg.append((fgm+0.5*f3gm)/fga)
box["eFG%"]=efg
box_ad=box[["Player","PPP","TS%","eFG%"]]
box_ad=box_ad.groupby("Player").mean()
data=box_ad.merge(o_pipm,on="Player")
data=data[data["PPP"]>0]
#PPPとO-PIPMの相関の確認
plt.plot(data["PPP"],data["O-PIPM"],"o")
plt.xlabel("PPP")
plt.ylabel("O-PIPM")
plt.title("correlation between PPP and O-PIPM")
plt.show()
print("PPPとO-PIPMの相関係数: ",data["PPP"].corr(data["O-PIPM"]))
#回帰直線入のPPPとO-PIPMの散布図を書く
model=LinearRegression()
model.fit(data[["PPP"]],data[["O-PIPM"]])
plt.plot(data["PPP"],data["O-PIPM"],"o")
plt.plot(data[["PPP"]],model.predict(data[["PPP"]]),linestyle="solid")
plt.xlabel("PPP")
plt.ylabel("O-PIPM")
plt.title("correlation between PPP and O-PIPM")
plt.show()
#print("モデルの回帰係数: ",model.coef_)
#print("モデルの切片: ",model.intercept_)
print("モデルの決定係数: ",model.score(data[["PPP"]],data["O-PIPM"]))
#dataにPPPでO-PIPMを回帰した時の予測値を加える
pred=model.predict(data[["PPP"]])
data=data.reset_index()
data["pred"]=pd.DataFrame(pred)
#dataに残差を加える
residual=[]
for o_pipm,pred in zip(data["O-PIPM"],data["pred"]):
residual.append(o_pipm-pred)
data["residuals"]=residual
#残差の大きい選手TOP25を抽出
data.sort_values("residuals",ascending=False).head(25)
#TS%とO-PIPMの相関の確認
plt.plot(data["TS%"],data["O-PIPM"],"o")
plt.xlabel("TS%")
plt.ylabel("O-PIPM")
plt.title("correlation between TS% and O-PIPM")
plt.show()
print("TS%とO-PIPMの相関係数: ",data["TS%"].corr(data["O-PIPM"]))
#回帰直線入のTS%とO-PIPMの散布図を書く
model=LinearRegression()
model.fit(data[["TS%"]],data[["O-PIPM"]])
plt.plot(data["TS%"],data["O-PIPM"],"o")
plt.plot(data[["TS%"]],model.predict(data[["TS%"]]),linestyle="solid")
plt.xlabel("TS%")
plt.ylabel("O-PIPM")
plt.title("correlation between TS% and O-PIPM")
plt.show()
#print("モデルの回帰係数: ",model.coef_)
#print("モデルの切片: ",model.intercept_)
print("モデルの決定係数: ",model.score(data[["TS%"]],data["O-PIPM"]))
#eFG%とO-PIPMの相関の確認
plt.plot(data["eFG%"],data["O-PIPM"],"o")
plt.xlabel("eFG%")
plt.ylabel("O-PIPM")
plt.title("correlation between eFG% and O-PIPM")
plt.show()
print("eFG%とO-PIPMの相関係数: ",data["eFG%"].corr(data["O-PIPM"]))
#回帰直線入のeFG%とO-PIPMの散布図を書く
model=LinearRegression()
model.fit(data[["eFG%"]],data[["O-PIPM"]])
plt.plot(data["eFG%"],data["O-PIPM"],"o")
plt.plot(data[["eFG%"]],model.predict(data[["eFG%"]]),linestyle="solid")
plt.xlabel("eFG%")
plt.ylabel("O-PIPM")
plt.title("correlation between eFG% and O-PIPM")
plt.show()
#print("モデルの回帰係数: ",model.coef_)
#print("モデルの切片: ",model.intercept_)
print("モデルの決定係数: ",model.score(data[["eFG%"]],data["O-PIPM"]))
Follow me!
