【入門】変動係数を使って『ガチャ感』のある選手を探そう!(Python編)【バスケのデータ分析】
こんにちは、らんそうるい(@rnsr0371)です。この記事では、バスケのデータ分析をやってみたい! という人向けに、一緒にコード(Pythonを使います)を書きながら、バスケのデータ分析を行ってみます。データハンドリング〜分析結果の出力までお付き合いください。テーマは変動係数という統計的な指標を使って『ガチャ感』のある選手を探そう! です。貴方をデータ分析の沼に誘いますね(ツユのニューアルバム『貴方を不幸に誘いますね』のリスペクトです)。
想定している読者は次のような感じです。
ここで分散という統計的な指標について考えてみます。分散$s^2$はデータ(ここでは一試合ごとの得点)のばらつきを表す指標で、次のように定義されます。$$s^2=\frac{1}{n}\sum_{i=1}^{n}(x_i-\bar{x})^2$$ここで、$\bar{x}$は平均、$i$はデータの番号、$n$はデータの個数です。つまり「各データの平均からの距離の2乗」の平均値です。です。選手Aと選手Bの分散を計算すると、選手Aは分散0、選手Bは分散80となります。選手AとBでは平均得点は同じですが、得点の分散は選手Bの方が大きいことが分かりました。分散の意味――ばらつきを数値化したものからも『ガチャ感』――試合ごとに出来に当たり外れがあると対応があるように私は感じます。
統計学の世界ではばらつきを表す指標は分散以外にもあります。分散の一つの難しさとして、計算結果が測定単位の2乗になってしまうということが挙げられます。つまり、分散の平方根をとってあげれば、測定単位が元に戻ります。分散の平方根のことを標準偏差といいます。
標準偏差を使っても、まだ問題は残ります。バスケの世界ではスター選手が平均20得点以上を記録するのに対して、ロールプレイヤーは平均10得点未満のこともしばしばです。平均が大きく異なるデータ同士の散らばりの比較は標準偏差では不適切です。スター選手のほうが標準偏差が大きくなりやすいからです。そこで、標準偏差を平均で割ってあげた指標、変動係数を算出してあげると良さげだと思います。変動係数(CV, coefficient of variation)の定義を書くと、$$CV=\frac{s}{\bar{x}}$$です。
以上の話をまとめると『ガチャ感』はデータの散らばりによって感じられる。統計学の世界ではデータの散らばりを評価する指標がいくつかあるが、バスケの特性(スター選手とロールプレイヤーでは平均得点にかなり差がある)を踏まえると変動係数を使ってばらつきを評価すると良さそう。となります。あとは、データを準備し、Pythonを走らせて、各選手の得点の変動係数を算出し、ランキングを表示させてあげれば『ガチャ感』のある選手を見つけられそうです。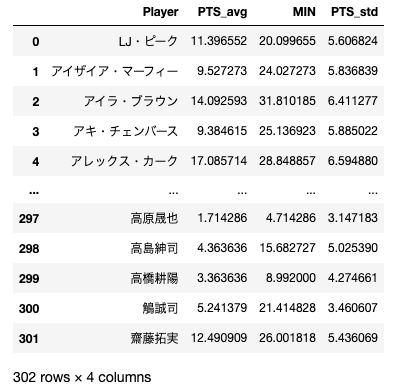
私もデータ分析初心者なので、皆さんのデータ分析の手順を見せていただきたいです。玄人の皆さんにはここは直したほうが良いよ! という点をご指摘いただけると泣いて喜びます。
もしこの記事が好評だったら、次は単純な可視化(データの見える化)でも面白いことができる! という記事を書きたいと思っています。よろしければ、Twitterなどで拡散していただけると嬉しいです。

想定している読者は次のような感じです。
- Pythonの基礎的な文法が分かる(if文とfor文が登場します)
- Jupyter Notebookを導入済み
- バスケに限らず、データ分析が初めて
『ガチャ感』と変動係数――日常用語を統計的な用語に落とし込もう!
まず『ガチャ感』という日常用語を統計的な用語に翻訳するために『ガチャ感』について考えます。次の2選手の試合ごとの得点について『ガチャ感』を感じるのはどちらでしょうか?- 選手A:20, 20, 20 ,20, 20(一試合平均20点)
- 選手B:10, 30, 10, 30, 20(一試合平均20点)
ここで分散という統計的な指標について考えてみます。分散$s^2$はデータ(ここでは一試合ごとの得点)のばらつきを表す指標で、次のように定義されます。$$s^2=\frac{1}{n}\sum_{i=1}^{n}(x_i-\bar{x})^2$$ここで、$\bar{x}$は平均、$i$はデータの番号、$n$はデータの個数です。つまり「各データの平均からの距離の2乗」の平均値です。です。選手Aと選手Bの分散を計算すると、選手Aは分散0、選手Bは分散80となります。選手AとBでは平均得点は同じですが、得点の分散は選手Bの方が大きいことが分かりました。分散の意味――ばらつきを数値化したものからも『ガチャ感』――試合ごとに出来に当たり外れがあると対応があるように私は感じます。
統計学の世界ではばらつきを表す指標は分散以外にもあります。分散の一つの難しさとして、計算結果が測定単位の2乗になってしまうということが挙げられます。つまり、分散の平方根をとってあげれば、測定単位が元に戻ります。分散の平方根のことを標準偏差といいます。
標準偏差を使っても、まだ問題は残ります。バスケの世界ではスター選手が平均20得点以上を記録するのに対して、ロールプレイヤーは平均10得点未満のこともしばしばです。平均が大きく異なるデータ同士の散らばりの比較は標準偏差では不適切です。スター選手のほうが標準偏差が大きくなりやすいからです。そこで、標準偏差を平均で割ってあげた指標、変動係数を算出してあげると良さげだと思います。変動係数(CV, coefficient of variation)の定義を書くと、$$CV=\frac{s}{\bar{x}}$$です。
以上の話をまとめると『ガチャ感』はデータの散らばりによって感じられる。統計学の世界ではデータの散らばりを評価する指標がいくつかあるが、バスケの特性(スター選手とロールプレイヤーでは平均得点にかなり差がある)を踏まえると変動係数を使ってばらつきを評価すると良さそう。となります。あとは、データを準備し、Pythonを走らせて、各選手の得点の変動係数を算出し、ランキングを表示させてあげれば『ガチャ感』のある選手を見つけられそうです。
データを用意しよう!
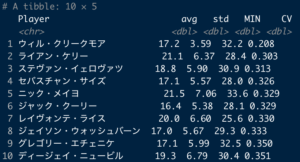
データ分析をするためにはデータが必要です。これはとても幸運なことだと思うのですが、バスケのデータ分析界隈には増田林太郎様という神がおられて、GitHub上にBリーグの各試合のボックススコアなどを公開されています。このデータはとても綺麗で前処理が必要ないので、このデータを生データとして使うことにします。teams.csvとgames_boxscore_202021.csvをダウンロードしてください。そして、列名を確認しておいてください。分析しよう!
データの整形
では、まず必要なライブラリをインポートします。ここでは、pandasとnumpyを使います。pandasをインポートすると、データフレーム型というとても都合の良いデータ型を扱えるようになります。numpyは欠損値を扱うためにインポートします。import pandas as pd
import numpy as npteams=pd.read_csv("data/teams.csv")
boxscore=pd.read_csv("data/games_boxscore_202021.csv")teams=teams[teams["Season"]=="2020-21"]
teams=teams[teams["League"]=="B1"]boxscore=teams.merge(boxscore,on="TeamId")avg=boxscore.groupby("Player").mean()std=boxscore.groupby("Player").std()avg=avg.reset_index()
std=std.reset_index()avg=avg.loc[:,["Player","PTS","MIN"]]
std=std.loc[:,["Player","PTS"]]data=avg.merge(std,on="Player",suffixes=("_avg","_std"))変動係数の計算
変動係数(CV)を計算しましょう! CVという空のリストを用意して、for文で一行ずつデータを取得し、計算結果をCVに追加していきます。一試合平均得点が0の場合、欠損値NaNをリストに追加するようにif文を書きます。もちろん、0で割るとエラーが出ます。最後に、CVという列名でdataにCVというリストを付け加えてあげます。CV=[]
for average,standard_deviation in zip(data["PTS_avg"],data["PTS_std"]):
if average==0:
CV.append(np.nan)
else:
CV.append(standard_deviation/average)
data["CV"]=CVランキングの表示
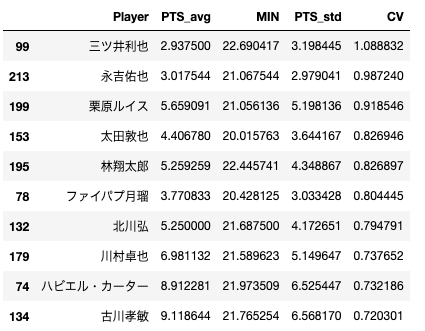
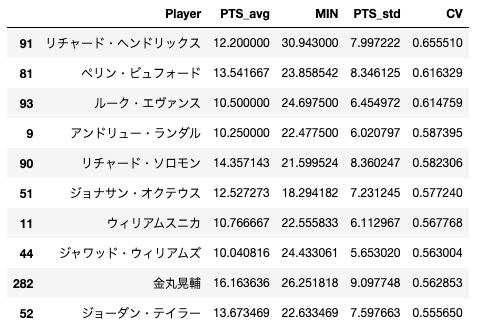
では、ランキングを表示させましょう! 平均20分以上出場している選手の中で、変動係数が高い選手TOP10を表示してみます。コードの流れとしては、まず出場時間が20分以上の選手を絞り込んで、次にCVで降順に並べ替え、最後に上から10行を表示、という感じです。sort_values()メソッドの引数byで並べ替えたい列名を指定して、ascending=Falseで降順ソートを指定します。Falseを指定しない場合は昇順ソートになります。head()メソッドで数字を引数にあげると、上から○番目までのデータが表示されます。ここではTOP10なので、10を渡してあげます。data[data["MIN"]>=20].sort_values(by="CV",ascending=False).head(10)data[data["PTS_avg"]>=10].sort_values(by="CV",ascending=False).head(10)終わりに
お付き合いいただきありがとうございました。推測統計や機械学習の高度な手法を使わなくても、記述的な指標だけで、意外と面白いことができるというのが実感していただけると嬉しいです。私もデータ分析初心者なので、皆さんのデータ分析の手順を見せていただきたいです。玄人の皆さんにはここは直したほうが良いよ! という点をご指摘いただけると泣いて喜びます。
もしこの記事が好評だったら、次は単純な可視化(データの見える化)でも面白いことができる! という記事を書きたいと思っています。よろしければ、Twitterなどで拡散していただけると嬉しいです。
Follow me!