【入門】選手の成長を可視化しよう!(Python編)【バスケのデータ分析】
こんにちは、らんそうるい(@rnsr0371)です。この記事では、バスケのデータ分析をやってみたい! という人向けに、一緒にコード(Python)を書きながら、バスケのデータ分析を行ってみます。テーマは選手の成長を可視化しよう! です。想定している読者は次のような感じです。
次の問題は、どのスタッツを使うかです。後述するrintaromasuda様のデータでは、EFFという選手の貢献度を表す指標が記録されているので、これを使うことにします。EFFの定義は次のとおりです。$$EFF=(PTS+REB+AST+STL) -(FG失敗数+FT失敗数+TO)$$右辺の前半の括弧の中はポジティブなスタッツを、後半の括弧の中はネガティブなスタッツを表しています。これらの差分がEFFです。
この記事では、選手の評価を反映するスタッツとしてEFFを用いますが、EFFはオールインワンスタッツとしては原始的です。もっと効果的に選手の評価を反映させたい場合にはPIPMなどの高度なオールインワンスタッツを使ってみるとよいと思います。
EFFはスタッツに残る貢献を(ある程度)反映していますが、スタッツに残らない貢献というのも気になるところです。スタッツに残らない貢献を評価するために、ここでは出場時間を使いたいと思います。出場時間はヘッドコーチの裁量によって決まります。出場時間が長いほど、ヘッドコーチからの評価が高いと考えられます。そして、その評価にはオフェンスだけではなく、ディフェンスからの視点も含まれていることが期待できます。また、オフェンス面からも、オフボールの動きやスペーシング、スクリーンプレーの上手さなどの視点が含まれていることでしょう。
以上の考えから、2020-21シーズンと2019-20シーズンのEFFの差と出場時間の差を算出して、これらを選手の成長の指標としたいと思います。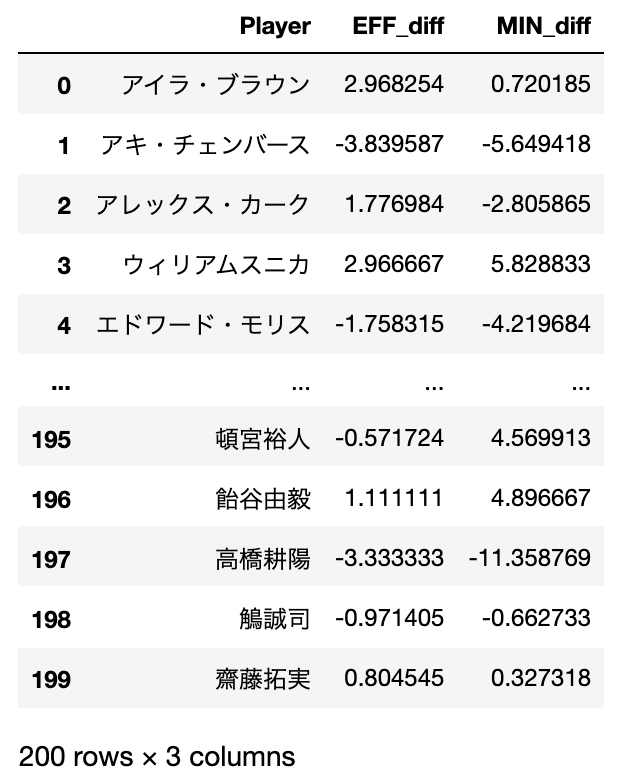
選手の成長というのは複雑で抽象的な概念ですが、その一部分であれば、スタッツを利用して評価できることができる、というのが実感していただけると嬉しいです。もっと分析を深めたいという方は、EFFの代わりにPIPMなどのもっと進んだアドバンスドスタッツを用いるといった改善ができると思います。ぜひチャレンジしてみてください。

- Pythonの基礎的な文法が分かる(for文が登場します)
- Jupyter Notebookを導入済み
- バスケに限らず、データ分析が初めて
選手の成長をどう評価するか?
選手の成長という概念は複雑かつ抽象的で、その全てをデータから捉えることは難しいです。そこで、この記事では2020-21シーズンと2019-20シーズンのスタッツの差をとって、成長の指標としたいと思います。次の問題は、どのスタッツを使うかです。後述するrintaromasuda様のデータでは、EFFという選手の貢献度を表す指標が記録されているので、これを使うことにします。EFFの定義は次のとおりです。$$EFF=(PTS+REB+AST+STL) -(FG失敗数+FT失敗数+TO)$$右辺の前半の括弧の中はポジティブなスタッツを、後半の括弧の中はネガティブなスタッツを表しています。これらの差分がEFFです。
この記事では、選手の評価を反映するスタッツとしてEFFを用いますが、EFFはオールインワンスタッツとしては原始的です。もっと効果的に選手の評価を反映させたい場合にはPIPMなどの高度なオールインワンスタッツを使ってみるとよいと思います。
EFFはスタッツに残る貢献を(ある程度)反映していますが、スタッツに残らない貢献というのも気になるところです。スタッツに残らない貢献を評価するために、ここでは出場時間を使いたいと思います。出場時間はヘッドコーチの裁量によって決まります。出場時間が長いほど、ヘッドコーチからの評価が高いと考えられます。そして、その評価にはオフェンスだけではなく、ディフェンスからの視点も含まれていることが期待できます。また、オフェンス面からも、オフボールの動きやスペーシング、スクリーンプレーの上手さなどの視点が含まれていることでしょう。
以上の考えから、2020-21シーズンと2019-20シーズンのEFFの差と出場時間の差を算出して、これらを選手の成長の指標としたいと思います。
データを用意しよう!
データ分析するためにはデータが必要です。rintaromasuda様のGitHubから、teams.csvとgames_boxscore201920.csv、games_boxscore202021.csvをダウンロードして、これらを生データとして使いたいと思います。分析しよう
データの整形
では、必要なライブラリをインポートします。pandasとmatplotlibを使います。pandasをインポートすると、データフレーム型というとても都合の良いデータ型を扱えるようになります。matplotlibは可視化用のライブラリです。#必要なライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt#データのインポート
teams=pd.read_csv("data/teams.csv")
boxscore2019=pd.read_csv("data/games_boxscore_201920.csv")
boxscore2020=pd.read_csv("data/games_boxscore_202021.csv")#teamsから2019-20シーズンのB1のデータだけ抽出
teams2019=teams[teams["Season"]=="2019-20"]
teams2019=teams2019[teams2019["League"]=="B1"]
#teamsから2020-21シーズンのB1のデータだけ抽出
teams2020=teams[teams["Season"]=="2020-21"]
teams2020=teams2020[teams2020["League"]=="B1"]
#boxscore2019からB1のデータだけを取り出す
boxscore2019=teams2019.merge(boxscore2019,on="TeamId")
#boxscore2020からB1のデータだけを取り出す
boxscore2020=teams2020.merge(boxscore2020,on="TeamId")#選手ごとに平均スタッツを算出する
boxscore2019=boxscore2019.groupby("Player").mean()
boxscore2020=boxscore2020.groupby("Player").mean()#boxscore2019とboxscore2020を選手名で結合する
data=boxscore2019.merge(boxscore2020,on="Player",suffixes=["_2019","_2020"])
#インデックスをリセットする
data=data.reset_index()#EFFの2019と2020の差分をとる
eff_diff=[]
for eff_2019,eff_2020 in zip(data["EFF_2019"],data["EFF_2020"]):
eff_diff.append(eff_2020-eff_2019)
data["EFF_diff"]=pd.DataFrame(eff_diff)
#出場時間の2019と2020の差分をとる
min_diff=[]
for min_2019,min_2020 in zip(data["MIN_2019"],data["MIN_2020"]):
min_diff.append(min_2020-min_2019)
data["MIN_diff"]=pd.DataFrame(min_diff)#必要な列だけ抽出する
data=data.loc[:,["Player","EFF_diff","MIN_diff"]]
#データの確認
data可視化しよう!
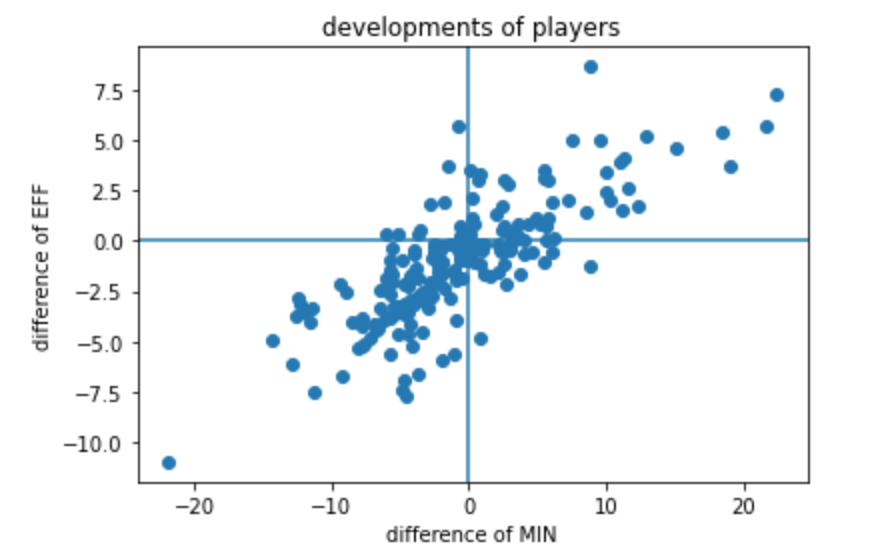
さて、EFFの差分と出場時間の差分が用意できたので、可視化してみましょう。2変数を同時に扱いたいので、散布図が適当だと思います。差分は0以上だと「成長している」と考えるので、分かりやすいように、EFFの差分(縦軸)と出場時間の差分(横軸)の値がそれぞれ0のところに直線を引きました。4分割されたエリアの内、右上にいる選手たちがEFFから見ても、出場時間から見ても、成長した選手だと言うことができます。#可視化する
plt.plot(data["MIN_diff"],data["EFF_diff"],"o")
plt.ylabel("difference of EFF")
plt.xlabel("difference of MIN")
plt.title("developments of players")
plt.axhline(0)
plt.axvline(0)
plt.show()#EFF_diffとMIN_diffの積をとって、散布図で右上にいる選手を探す
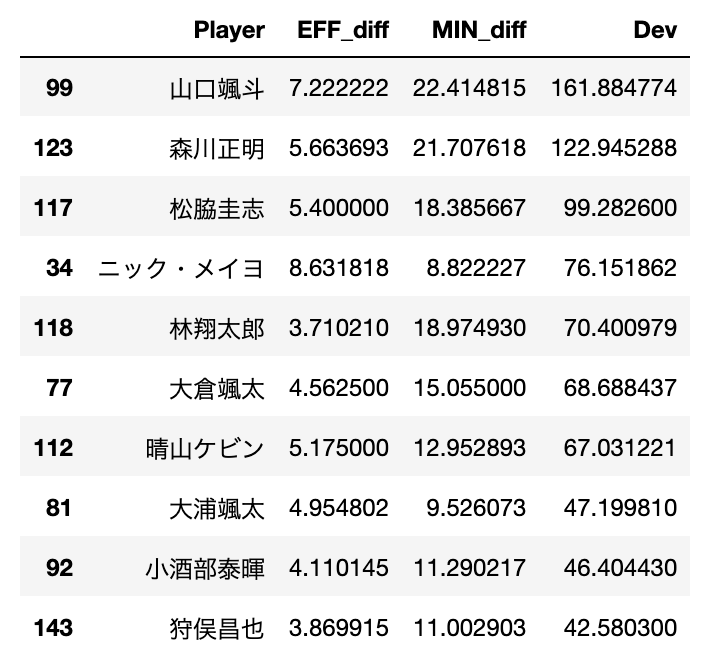
dev=[]
for eff_diff,min_diff in zip(data["EFF_diff"],data["MIN_diff"]):
dev.append(eff_diff*min_diff)
data["Dev"]=pd.DataFrame(dev)
#Devが高い選手ベスト10を表示
#(EFF_diffをを0以上の選手の中から探すことで、マイナス掛けるマイナスで積が正になっている選手を取り除ける)
data[data["EFF_diff"]>=0].sort_values("Dev",ascending=False).head(10)終わりに
お付き合いいただきありがとうございました。この記事では、選手の成長を可視化しよう! というテーマで分析を行いました。選手の成長を昨シーズンと比べたEFFの伸び・出場時間の伸びで評価し、これらのデータから散布図を描きました。EFFの伸びと出場時間の伸びの積が大きい選手(散布図上で右上のエリアにいる選手)を調べたところ、特別指定選手と移籍組の評価が高いということが分かりました。これは直感に一致する結果だと思います。選手の成長というのは複雑で抽象的な概念ですが、その一部分であれば、スタッツを利用して評価できることができる、というのが実感していただけると嬉しいです。もっと分析を深めたいという方は、EFFの代わりにPIPMなどのもっと進んだアドバンスドスタッツを用いるといった改善ができると思います。ぜひチャレンジしてみてください。
Follow me!

