出場時間の影響を取り除いて『ガチャ感』を調べる
こんにちは、らんそうるい(@rnsr0371)です。先日「変動係数を使って『ガチャ感』のある選手を探そう!(R編, Python編)」 という、バスケのデータ分析の入門記事を公開しました。Twitterでのいいね/RTありがとうございました。
この記事について、Twitterに寄せられたリプライで気になるものがあったので、紹介させてください。リプライはほせ(バスケのデータ分析)様から寄せられたもので「出場時間の考慮があるともっと面白くなりそうかなと思います(試合ごとの出場時間の大小が得点の大小にも絡むので)」というものです。
ご指摘はごもっともで、出場時間の大小(ばらつき)によって、得点の大小は変わりえます。つまり、変動係数で評価した得点のばらつきの内、出場時間のばらつきで説明できる部分が少なからずある可能性があります。試合ごとのムラを評価するために得点の変動係数を調べたわけですが、ムラではなくて、出場時間のばらつきによって得点のばらつきが説明されてしまうとすれば『ガチャ感』のある選手を見つける、という目標から少し遠いことをしていたことになります。
そこでこの記事では、出場時間の影響を取り除いた上で得点のばらつきを評価して、真の『ガチャ感』ある選手を探してみたいと思います。
この記事の内容は統計学の入門者・初学者(「マンガでわかる統計学[回帰分析編]」を読んだことのある人を想定)のレベルを超えていると思います。しかし、この記事は入門記事の続編として書いたので、どんな処理をしたのか分かるように、文章中にコードを埋め込んであります。入門者・初学者の皆さんの参考になれば幸いです。文章の最後には、分析に用いたコードの全体を載せました。記事内ではRを使っておりますが、Pythonで同じ分析をするコードをGitHubに掲載してあります。Python使いの方はGitHubをご覧ください。
残差というのは、単回帰モデルの予測値と実際の値との差のことです。南風原(2002)「心理統計学の基礎」によると、単回帰分析を行うことにより、従属変数(得点)を独立変数(出場時間)と完全に相関する成分(予測値)と全く相関しない成分(残差)に分解することができます。数学的な証明は同書の7章に載っているので、ご興味のある方はぜひ読んでみてください。「心理統計学の基礎」は統計学を勉強する人がバイブルに挙げることもある、とても良いテキストです。
得点を出場時間で単回帰分析したときの残差は「出場時間の割に得点が多い/少ない」ことを表すと考えられ、単純な得点よりも純粋な得点能力を反映しています。そして、残差のばらつきは、試合ごとの調子によって、その得点能力が発揮できたかどうかを反映していると解釈できます。残差に注目することによって、より『ガチャ感』ある選手を見つけることができるはずです。
パーシャルアウトと1分あたりの得点、どちらが望ましいのかという点については、勉強不足で分かりません。手元にある統計学のテキストやインターネットの日本語の記事には言及はありませんでした。
私がパーシャルアウトという方法を選択したのは、私が学んだ心理学の分野ではパーシャルアウトの方が一般的だったからです(研究ではパーシャルアウトそのものというよりは、その応用である重回帰分析で偏回帰係数を調べるとか、共分散分析で何かの影響を取り除いて実験操作の効果を調べるといったことが行われています)。心理学における統計的な処理を踏襲していると言えば聞こえはいいですが、実際には惰性です。
なぜ心理学の分野では「○あたりの何か」よりもパーシャルアウトの方が一般的なのか考えたときに思いついたのは、心理学の分野では測定単位がはっきりしていないことが多いという理由です。たとえば「ローゼンバーグの自尊心尺度1点あたり〇〇」という評価をしたとしても、自尊心尺度1点の意味がはっきりしません。ならば、自尊心の影響をパーシャルアウトした方が分かりやすいと思います。
翻って、バスケのデータ分析における「1分あたりの得点」というのは、心理学のデータ分析と違って、意味が分かりやすいと思います。解釈のしやすさという点で評価すれば、バスケのデータ分析ではパーシャルアウトよりも1分あたり得点の方が望ましいかもしれません。
パーシャルアウトと1分あたりの得点、どちらが好ましいのか統計学有識者様のお考えをお聞かせいただければ幸いです。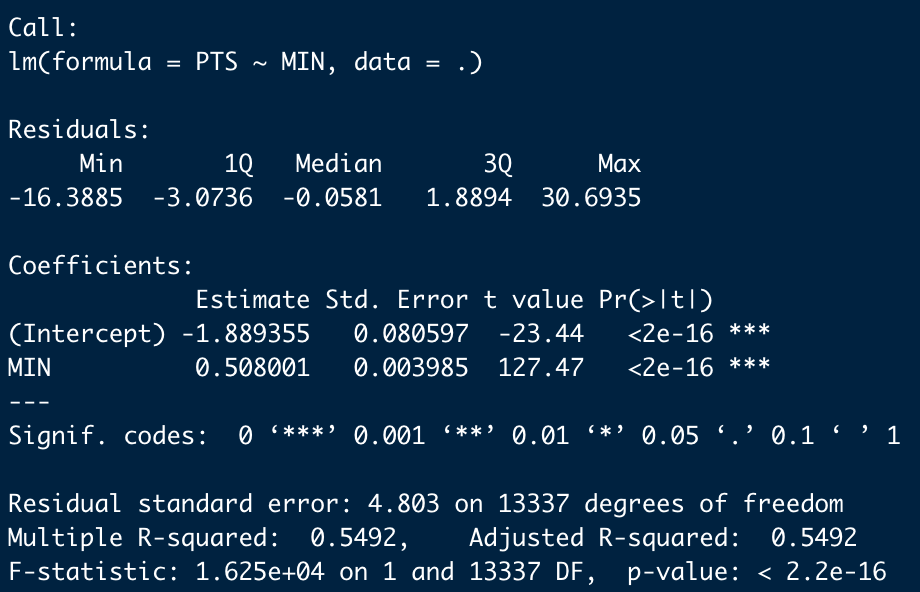




角野選手のプレーは拝見したことがないのですが、2020-21シーズンはルーキーシーズンだったようです(若きエースがCSで見せた成長曲線参照)。ルーキーなら大ハズレの試合があっても仕方ないのかなと思います。今後の成長に期待ですね。

この記事について、Twitterに寄せられたリプライで気になるものがあったので、紹介させてください。リプライはほせ(バスケのデータ分析)様から寄せられたもので「出場時間の考慮があるともっと面白くなりそうかなと思います(試合ごとの出場時間の大小が得点の大小にも絡むので)」というものです。
ご指摘はごもっともで、出場時間の大小(ばらつき)によって、得点の大小は変わりえます。つまり、変動係数で評価した得点のばらつきの内、出場時間のばらつきで説明できる部分が少なからずある可能性があります。試合ごとのムラを評価するために得点の変動係数を調べたわけですが、ムラではなくて、出場時間のばらつきによって得点のばらつきが説明されてしまうとすれば『ガチャ感』のある選手を見つける、という目標から少し遠いことをしていたことになります。
そこでこの記事では、出場時間の影響を取り除いた上で得点のばらつきを評価して、真の『ガチャ感』ある選手を探してみたいと思います。
この記事の内容は統計学の入門者・初学者(「マンガでわかる統計学[回帰分析編]」を読んだことのある人を想定)のレベルを超えていると思います。しかし、この記事は入門記事の続編として書いたので、どんな処理をしたのか分かるように、文章中にコードを埋め込んであります。入門者・初学者の皆さんの参考になれば幸いです。文章の最後には、分析に用いたコードの全体を載せました。記事内ではRを使っておりますが、Pythonで同じ分析をするコードをGitHubに掲載してあります。Python使いの方はGitHubをご覧ください。
パーシャルアウトで出場時間の影響を取り除く
残差というのは、単回帰モデルの予測値と実際の値との差のことです。南風原(2002)「心理統計学の基礎」によると、単回帰分析を行うことにより、従属変数(得点)を独立変数(出場時間)と完全に相関する成分(予測値)と全く相関しない成分(残差)に分解することができます。数学的な証明は同書の7章に載っているので、ご興味のある方はぜひ読んでみてください。「心理統計学の基礎」は統計学を勉強する人がバイブルに挙げることもある、とても良いテキストです。
得点を出場時間で単回帰分析したときの残差は「出場時間の割に得点が多い/少ない」ことを表すと考えられ、単純な得点よりも純粋な得点能力を反映しています。そして、残差のばらつきは、試合ごとの調子によって、その得点能力が発揮できたかどうかを反映していると解釈できます。残差に注目することによって、より『ガチャ感』ある選手を見つけることができるはずです。
【こぼれ話】出場時間の影響の取り除き方について
この記事では出場時間の影響を取り除く方法として、パーシャルアウトという方法を使いました。しかし、出場時間の影響を取り除く方法として、1分あたりの得点を使うという方法もありえます。パーシャルアウトと1分あたりの得点、どちらが望ましいのかという点については、勉強不足で分かりません。手元にある統計学のテキストやインターネットの日本語の記事には言及はありませんでした。
私がパーシャルアウトという方法を選択したのは、私が学んだ心理学の分野ではパーシャルアウトの方が一般的だったからです(研究ではパーシャルアウトそのものというよりは、その応用である重回帰分析で偏回帰係数を調べるとか、共分散分析で何かの影響を取り除いて実験操作の効果を調べるといったことが行われています)。心理学における統計的な処理を踏襲していると言えば聞こえはいいですが、実際には惰性です。
なぜ心理学の分野では「○あたりの何か」よりもパーシャルアウトの方が一般的なのか考えたときに思いついたのは、心理学の分野では測定単位がはっきりしていないことが多いという理由です。たとえば「ローゼンバーグの自尊心尺度1点あたり〇〇」という評価をしたとしても、自尊心尺度1点の意味がはっきりしません。ならば、自尊心の影響をパーシャルアウトした方が分かりやすいと思います。
翻って、バスケのデータ分析における「1分あたりの得点」というのは、心理学のデータ分析と違って、意味が分かりやすいと思います。解釈のしやすさという点で評価すれば、バスケのデータ分析ではパーシャルアウトよりも1分あたり得点の方が望ましいかもしれません。
パーシャルアウトと1分あたりの得点、どちらが好ましいのか統計学有識者様のお考えをお聞かせいただければ幸いです。
分析
生データの用意
rintaromasuda様のGitHubから、teams.csvとgames_boxscore_202021.csvを生データとして使いました。#必要なライブラリのインポート
library(tidyverse)
#データのインポート
teams=read_csv("data/teams.csv")
boxscore=read_csv("data/games_boxscore_202021.csv")データの整形
teams.csvからB1 2020-21シーズンのTeamIdを抽出し、games_boxscore_202021.csvからB1の選手のボックススコアだけを取り出しました。#teamsから2020-21_B1のデータだけ抜き出す
teams=teams %>% filter(League=="B1") %>% filter(Season=="2020-21")
#boxscoreからB1のデータだけ抜き出す
boxscore=teams %>% left_join(boxscore,by="TeamId")得点を出場時間で単回帰分析した結果
得点を出場時間で単回帰分析した結果、出場時間のばらつきによって、得点のばらつきの約55%が説明できることが分かりました。また、1分出場時間が増える度に、得点が0.5点増えるという関係があることが分かりました。そして、残差をboxscoreに追加しました。#MINでPTSを回帰する線形回帰モデルを立てる
model=boxscore %>% lm(PTS~MIN,data=.)
#modelの決定係数の確認
summary(model)#0.549
#モデルの残差をboxscoreに追加する
boxscore=boxscore %>% mutate(res=model$residuals)残差の記述統計量
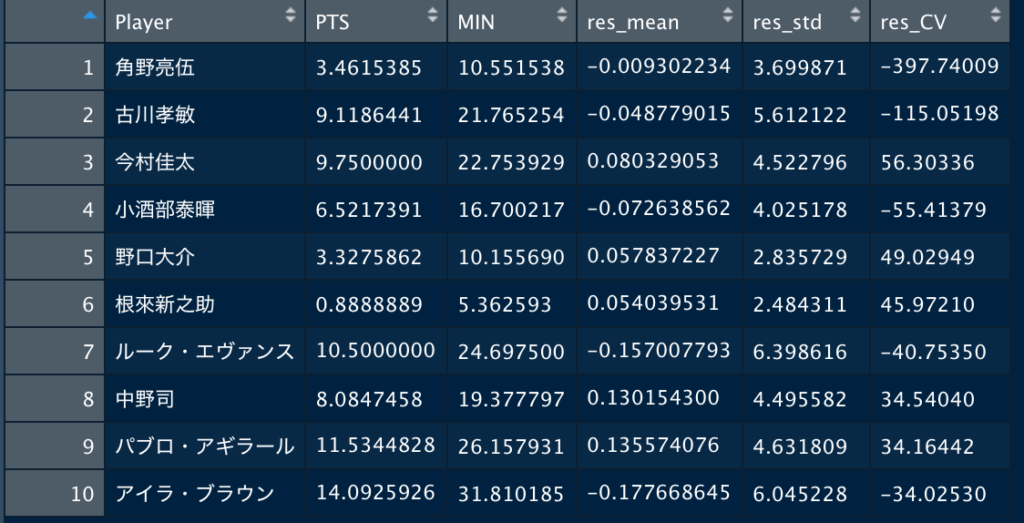
残差を選手ごとに集計し、全選手の平均と標準偏差を計算しました。その結果、残差の平均は0.14、標準偏差は2.53でした。残差の最大値は8.86で、最小値は-6.70でした。残差のレンジが15.56あったため、選手ごとに残差のばらつきを評価する際、標準偏差を使うよりも、変動係数を使う方が適切だと考えました。#残差の要約統計量・ヒストグラムを表示
summary(boxscore$res)
boxscore %>% ggplot(aes(x=res))+geom_histogram()+xlab("残差")+ggtitle("データ全体の残差の平均のヒストグラム")
#残差を選手ごとに集計
data=boxscore %>% group_by(Player) %>%
summarise(PTS=mean(PTS),MIN=mean(MIN),res_mean=mean(res),res_std=sd(res))
#残差の記述統計量の確認
summary(data$res_mean)
sd(data$res_mean)
summary(data$res_std)
data %>% ggplot(aes(x=res_mean))+geom_histogram()+xlab("選手ごとの残差の平均")+ggtitle("選手ごとの残差の平均のヒストグラム")
data %>% ggplot(aes(x=res_std))+geom_histogram()+xlab("選手ごとの残差の標準偏差")+ggtitle("選手ごとの残差の標準偏差のヒストグラム")残差の変動係数によるランキング
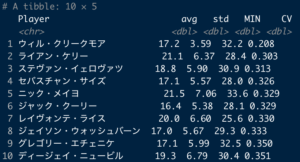
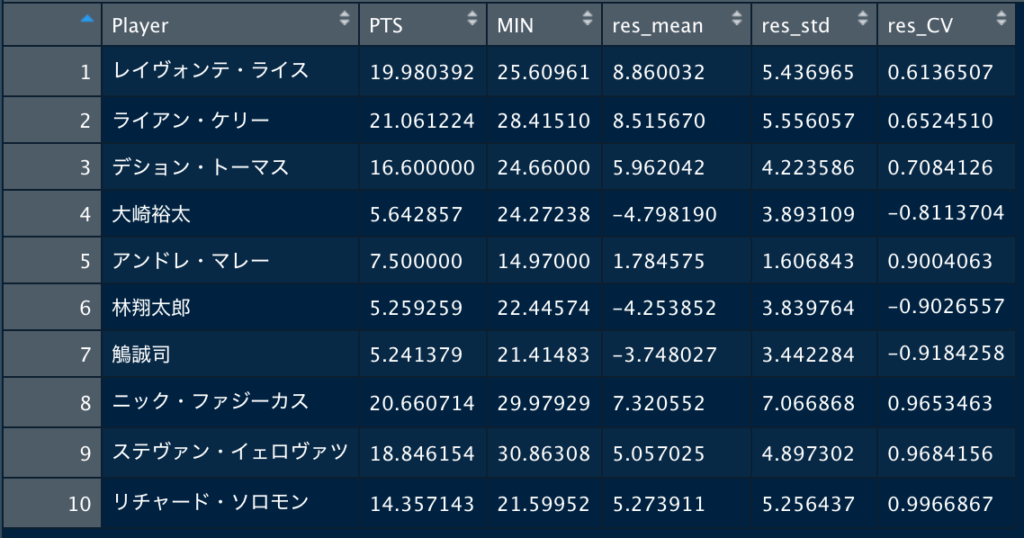
選手ごとに残差の平均と標準偏差を算出し、標準偏差を平均で割って、変動係数を求めました。その上で、変動係数の絶対値が大きい選手TOP10を表示しました。PTSは平均得点、MINは出場時間、res_meanは残差の平均、res_stdは残差の標準偏差、res_CVが残差の変動係数です。最も残差の変動係数(res_CV)の絶対値が大きいのは角野亮伍選手という結果が得られました。#残差の変動係数を算出
data=data %>% mutate(res_CV=res_std/res_mean)
#変動係数の絶対値でランキングを表示
#絶対値が大きい選手
rank=data %>% arrange(desc(abs(res_CV))) %>% head(10)
show(rank)
#平均得点が5点以上で絶対値が小さい選手
rank=data %>% filter(PTS>=5) %>% arrange(abs(res_CV)) %>% head(10)
show(rank)#変動係数が小さい選手(ライス選手)と大きい選手(角野選手)のヒストグラムを表示
boxscore %>% filter(Player=="レイヴォンテ・ライス") %>%
ggplot(aes(.$res))+
geom_histogram()+
xlab("得点を出場時間で回帰したときの残差")+
ylab("試合数")+
ggtitle("レイヴォンテ・ライス選手の残差のヒストグラム")
boxscore %>% filter(Player=="角野亮伍") %>%
ggplot(aes(.$res))+
geom_histogram()+
xlab("得点を出場時間で回帰したときの残差")+
ylab("試合数")+
ggtitle("角野亮伍選手の残差のヒストグラム")終わりに
この記事では、パーシャルアウトという方法で出場時間の影響を取り除いて、得点のばらつきが大きい選手、つまり『ガチャ感』のある選手を探してみました。パーシャルアウトした変数の変動係数を使って『ガチャ感』の評価を行った結果、角野亮伍選手が最も『ガチャ感』の強い選手であるという結果が得られました。また、ヒストグラムによる考察から、角野選手には「アタリ」の試合が少なく、時々「大ハズレ」の試合があることが分かりました。角野選手のプレーは拝見したことがないのですが、2020-21シーズンはルーキーシーズンだったようです(若きエースがCSで見せた成長曲線参照)。ルーキーなら大ハズレの試合があっても仕方ないのかなと思います。今後の成長に期待ですね。
分析に使ったコード(R)
#必要なライブラリのインポート
library(tidyverse)
#データのインポート
teams=read_csv("data/teams.csv")
boxscore=read_csv("data/games_boxscore_202021.csv")
#teamsから2020-21_B1のデータだけ抜き出す
teams=teams %>% filter(League=="B1") %>% filter(Season=="2020-21")
#boxscoreからB1のデータだけ抜き出す
boxscore=teams %>% left_join(boxscore,by="TeamId")
#MINでPTSを回帰する線形回帰モデルを立てる
model=boxscore %>% lm(PTS~MIN,data=.)
#modelの決定係数の確認
summary(model)#0.549
#モデルの残差をboxscoreに追加する
boxscore=boxscore %>% mutate(res=model$residuals)
#残差の要約統計量・ヒストグラムを表示
summary(boxscore$res)
boxscore %>% ggplot(aes(x=res))+geom_histogram()+xlab("残差")+ggtitle("データ全体の残差のヒストグラム")
#残差を選手ごとに集計
data=boxscore %>% group_by(Player) %>%
summarise(PTS=mean(PTS),MIN=mean(MIN),res_mean=mean(res),res_std=sd(res))
#残差の記述統計量の確認
summary(data$res_mean)
sd(data$res_mean)
summary(data$res_std)
data %>% ggplot(aes(x=res_mean))+geom_histogram()+xlab("選手ごとの残差の平均")+ggtitle("選手ごとの残差の平均のヒストグラム")
data %>% ggplot(aes(x=res_std))+geom_histogram()+xlab("選手ごとの残差の標準偏差")+ggtitle("選手ごとの残差の標準偏差のヒストグラム")
#ランキングの表示
rank=data %>% arrange(desc(res_std)) %>% head(10)
rank
#残差の変動係数を算出
data=data %>% mutate(res_CV=res_std/res_mean)
#変動係数の絶対値でランキングを表示
#絶対値が大きい選手
rank=data %>% arrange(desc(abs(res_CV))) %>% head(10)
show(rank)
#平均得点が5点以上で絶対値が小さい選手
rank=data %>% filter(PTS>=5) %>% arrange(abs(res_CV)) %>% head(10)
show(rank)
#変動係数が小さい選手(ライス選手)と大きい選手(角野選手)のヒストグラムを表示
boxscore %>% filter(Player=="レイヴォンテ・ライス") %>%
ggplot(aes(.$res))+
geom_histogram()+
xlab("得点を出場時間で回帰したときの残差")+
ylab("試合数")+
ggtitle("レイヴォンテ・ライス選手の残差のヒストグラム")
boxscore %>% filter(Player=="角野亮伍") %>%
ggplot(aes(.$res))+
geom_histogram()+
xlab("得点を出場時間で回帰したときの残差")+
ylab("試合数")+
ggtitle("角野亮伍選手の残差のヒストグラム")
Follow me!